
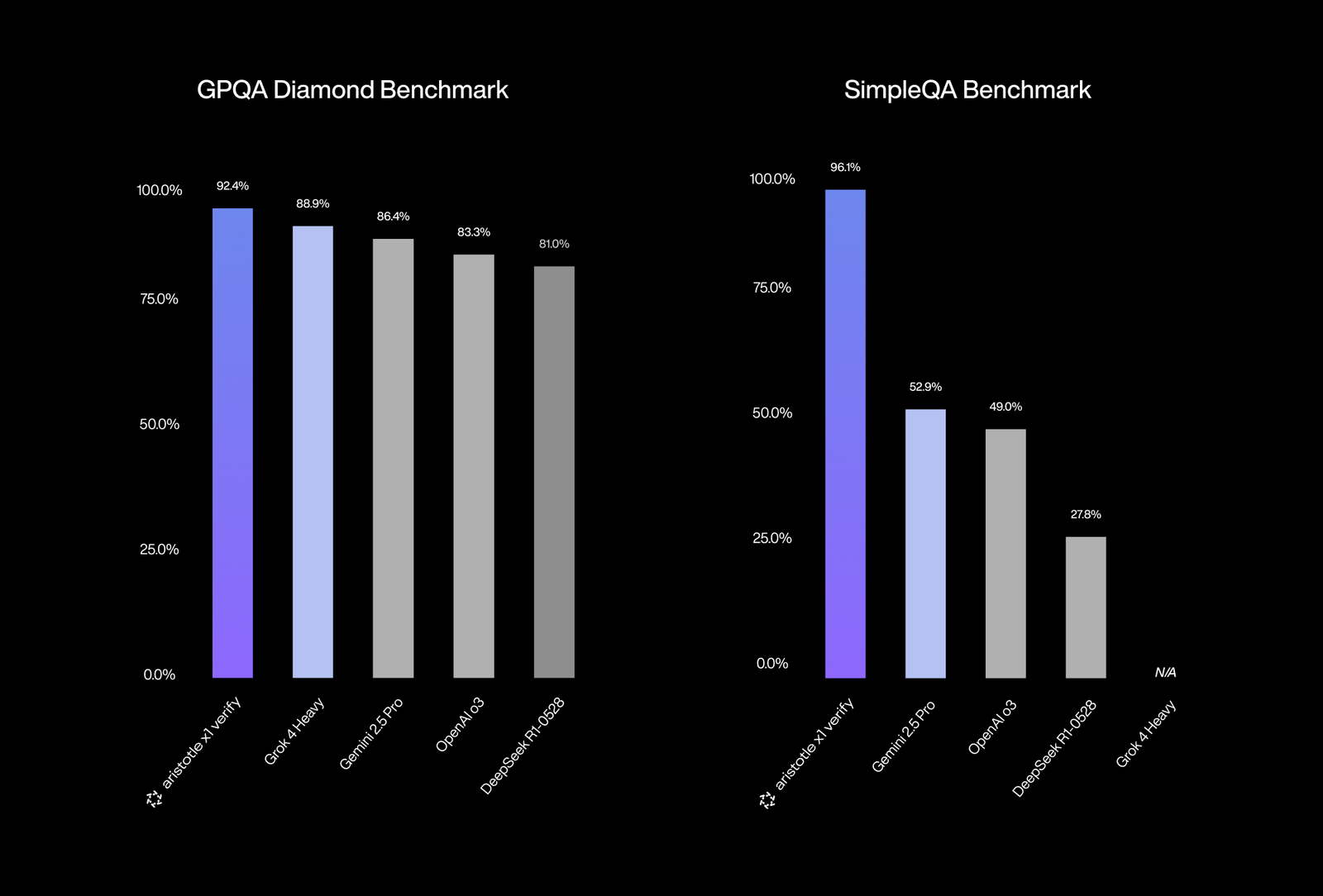
Today, we’re announcing that our AI co-scientist has achieved 92.4% accuracy on GPQA Diamond, one of the most rigorous scientific reasoning benchmarks, and 96.1% on SimpleQA, OpenAI’s factuality benchmark. This performance surpasses every major AI system, including xAI’s Grok 4 Heavy (88.9% GPQA), Google’s Gemini 2.5 Pro (86.4% GPQA, 52.9% SimpleQA), OpenAI’s o3 (83.3% GPQA, 49.0% SimpleQA), and Anthropic’s Claude Sonnet 4 (78.2% GPQA).
More importantly, we’re announcing new funding led by Informed Ventures to accelerate our mission: building the foundation for scientific superintelligence.
The most dangerous phrase in science isn’t “I don’t know” but “I’m certain”
Charles Sanders Peirce called it fallibilism: the recognition that all scientific knowledge is provisional, perpetually open to revision in light of new evidence. This principle (that uncertainty is a permanent condition of empirical inquiry) has driven every major scientific breakthrough.
We’ve built the first AI that embodies this principle.
Why current AI fails at real science
Reasoning models generally excel at GPQA Diamond but struggle catastrophically with SimpleQA, and this split exposes fundamental limitations in their scientific abilities.
GPQA Diamond consists of PhD-level multiple-choice questions requiring multi-step logical reasoning. Models like o3 score 83.3% here because they’ve learned to mimic expert-like thought patterns through chain-of-thought reasoning. They can follow complex logical sequences and analyze patterns in structured problems.
SimpleQA tests something entirely different: whether models actually know basic facts and can recognize when they don’t. Despite being “simple” questions, top models like o3 score only 49.0% and Gemini 2.5 Pro scores 52.9% because they confidently invent answers when they lack knowledge. They can’t distinguish between what they truly know versus what they’re pattern-matching.
This reveals the core problem: these models excel at simulating reasoning but lack genuine understanding. They can “fake” multi-step logic in structured settings but slip on elementary facts because they don’t know what they don’t know.
Our system achieves state-of-the-art performance on both benchmarks because we’ve built systematic verification directly into the reasoning process. Rather than emotional doubt, our models apply procedural self-skepticism to their outputs, making the skepticism reliable and scalable rather than unpredictable.
Other models embody the opposite of scientific thinking. They’re trained to sound confident about everything, when science requires knowing when you don’t know.
Towards scientific superintelligence
The Socratic and Cartesian embrace of doubt found its ultimate expression in modern science’s institutionalized fallibilism. Scientists don’t just tolerate uncertainty; they actively seek it out, designing experiments to prove themselves wrong.
Our AI applies this same systematic skepticism. When evidence is incomplete, it acknowledges limitations. When multiple theories compete, it weighs them appropriately. When calculations involve uncertainty, it propagates that uncertainty through its reasoning.
Solving calibration at this level creates possibilities that become apparent once you understand what calibration actually enables. This represents the foundation for AI that can eventually operate laboratories autonomously and pursue discoveries beyond human imagination.
New funding
We’ve completed a recent funding round led by Informed Ventures, with participation from Mike Mahlkow, Cross Atlantic Angels, Tomas Urena Munoz, among others.
“Autopoiesis solves a critical barrier for the adoption of AI models by scientists: reliably generating accurate outputs without hallucinating. Scientific superintelligence has the potential to turbocharge scientific discovery in a way not seen since the discovery of the scientific method. Joseph and the team have built the best performing model specifically designed for scientists, and the exceptional performance of Aristotle will drive exponential adoption by frontline scientists looking to accelerate their research with a trusted co-pilot.”
— Sunny Kumar, MD, Partner at Informed Ventures
Join us
Calibration isn’t just a nice-to-have; we believe it’s the fundamental requirement for AI that can advance science. To achieve 92.4% GPQA Diamond performance while maintaining exceptional calibration, we had to fundamentally rethink how AI systems handle uncertainty. Our training methodology embeds systematic doubt into every layer of reasoning, teaching models when to be confident and when to acknowledge limitations. Scientific superintelligence demands this level of epistemic rigor.
We are a small team building the foundation for AI-assisted scientific discovery and are hiring more researchers and engineers to accelerate breakthrough research and deploy our next-generation models.
Current AI reasoning architectures fundamentally conflict with scientific methodology. We are hiring specialists in uncertainty quantification, Bayesian reasoning, and calibration techniques to work alongside our founding team in developing novel training paradigms.
Scientific AI systems will eventually operate autonomous laboratories and make discoveries that reshape human knowledge. Such systems must be held to the highest standards of accuracy and epistemic humility. We are building a team dedicated to ensuring our AI maintains scientific integrity at scale.
The most profound discoveries await those willing to embrace uncertainty as a feature, not a bug.
Free early access for select researchers. Limited spots available. Apply here.
Autopoiesis: From Greek “auto” (self) + “poiesis” (creation).